【Dify】Lesson5-2:ナレッジの詳細設定方法と考え方

1つ前の記事で社内FAQチャットボットを作りましたが、質問の内容によっては「資料は入っているのに答えがズレる」「それっぽいけど肝心なところが出てこない」といった場面が出てきたかもしれません。
この差を生む一番の要因が、Difyのナレッジ設定です。
今回は、ナレッジの設定画面を見ながら、どこをどう調整すれば精度が上がるのかを、迷いにくい順番で整理していきます。
細かい数値をいきなり暗記するよりも、「この設定は何に効くのか」「困ったときにどこを触ればいいのか」を先に掴むのが近道です。

今回は文章量が多くて手を動かすことが少ないです…
どうしても眠くなっちゃうなら、この記事に「何が書いてあるか」だけを理解して、必要になった時に戻ってくるのでもいいと思うよ。
Lesson1:Dify入門|環境構築と最初の生成AIアプリ開発
Lesson2:まずは体験|基本的なアプリを4つ作ろう
Lesson3:文章業務の自動化|実務で使えるアプリを開発しよう
Lesson4:ファイル処理で広がるDifyアプリ開発
Lesson5:RAG実践|ナレッジ検索アプリを作ろう
・Lesson5-1:RAGアプリ入門|社内FAQチャットボットを作ろう
・Lesson5-2:ナレッジの詳細設定方法と考え方 ◁今回はここ
・Lesson5-3:賢いRAGアプリを作ろう|クエリ変換とメモリ活用
Lesson6:機能拡張と外部システム連携|ツールを使いこなそう
Lesson7:総仕上げ|準備を整えて生成AIアプリ開発者へ
<<前のページ

Difyの記事一覧

次のページ>>

Difyナレッジ設定の全体像:データソース・チャンク・検索の3要素

ナレッジ設定は項目が多く見えますが、やっていることは大きく3つに分けられます。
ここを押さえておくと、画面を見たときに「今どの工程を調整しているのか」がはっきりして、設定迷子になりにくくなります。
- どのデータを入れるか(データソース)
- どう区切って覚えさせるか(チャンク)
- どう探して持ってくるか(検索・Rerank)
この3つは独立しているようで、実際はつながっています。
たとえば「検索が弱い」と感じても、原因がチャンクの切り方だった、ということが普通にあります。
なので、設定は一気に変えず、上流から順に見ていくのがコツです。
1. データソース:入れる情報の選び方
まず土台になるのが、ナレッジに入れる元データです。
ここは「量を増やせば強くなる」というより、質問に対して答えとして使える情報が入っているかどうかが重要です。
たとえばFAQチャットボットの場合、回答に必要なのは “社内ルールの結論” や “手順の確定版” です。
途中経過の議事録や、古いバージョンの手順書が混ざると、検索で拾われたときに回答がブレやすくなります。
2. チャンク:区切り方で回答のズレが決まる
チャンクは、ナレッジを検索するときの「ヒットする最小単位」だと思っておくと分かりやすいです。
ナレッジベースに保管された資料はチャンクという細かい部品に分解されています。
検索するときは資料全体じゃなくてどれかのチャンクを探して持ってくることになるよ。
ここが雑だと、検索が当たっているのに答えがズレます。
理由はシンプルで、持ってきた文章の中に “質問に必要な部分” と “関係ない部分” が混ざりやすくなるからです。
逆に、区切り方が適切だと、少ない情報でもズバッと根拠が出て、回答が安定します。
この記事の後半では、設定画面のキャプチャを見ながら「最大チャンク長」「オーバーラップ」「前処理ルール」をどう考えると失敗しにくいかを、具体例つきで整理します。
3. 検索・Rerank:拾う量と順位を安定させる
最後が検索設定です。ここは「質問文から、どのチャンクを何個拾ってくるか」を決める場所で、精度と安定感に直結します。
たとえば、持ってくる数を増やすと情報は増えますが、ノイズも混ざりやすくなります。
今回のゴールは、「検索が弱い」と感じたときに、いきなりプロンプトを疑うのではなく、ナレッジ設定のどこに手を入れるべきか当たりを付けられる状態になることです。
次の章から、キャプチャを使って実際の画面設定を見ていきます。
データソース選びと事前整形:ファイル/Notion/サイト同期のコツ
まずはナレッジに「何を入れるか」を具体的に詰めていきます。
RAGの精度はチャンクや検索設定で大きく変わりますが、そもそも元データが散らかっていると、どんな設定でも当たりにくくなります。
まずはデータソースを正しく選び、入れる前に軽く整えるところから始めましょう。
取り込み方法3種類(ファイル・Notion・ウェブ同期)
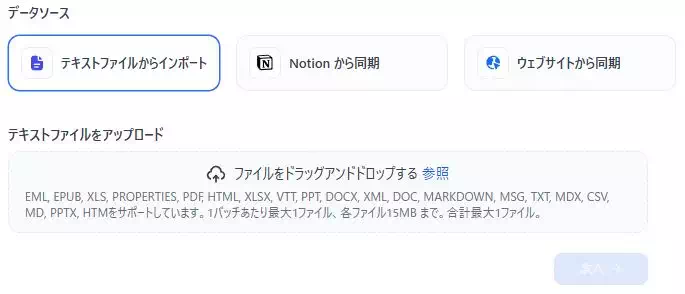
Difyのナレッジは、画面上で大きく3つの方法で取り込めます。
用途によって向き不向きがあるので、あなたの「FAQの元ネタ」がどこにあるかで選ぶのが一番ラクです。
代表的には次の3つです。
- テキストファイルからインポート(PDF、DOCX、MD、CSVなど)
- Notionから同期(Notionを正にして継続更新したい場合)
- ウェブサイトから同期(社内ポータルや公開FAQなど)
FAQが「完成版のファイル」として固まっているなら、まずはテキストファイルのインポートが手堅いです。
逆に、運用しながら更新していくFAQなら、Notion同期のほうが更新漏れが起きにくくなります。
ウェブサイト同期は、URL上のFAQが頻繁に変わる環境で便利ですが、ページ内の余計な要素(メニューやフッター)が混ざりやすいので、後述の “整形” がより重要になります。
基本的には、資料を作りこんだ上でテキストファイルとしてインポートすることが中心となるでしょう。
Notionはメモ・ドキュメント・タスク管理・社内Wikiなどを「1つのワークスペース」で扱える、クラウド型の生産性ツールだよ。
RAG精度が上がる資料整形
ここでいう整形は、凝った前処理ではありません。
「検索される前提」で、資料の形を少しだけ寄せる作業です。これをやるだけで、後のチャンク調整がかなり楽になります。
たとえばFAQチャットボットなら、効果が出やすい整形ポイントは次のとおりです。
- 1つの質問と回答が、なるべく近い場所にまとまっている(Qだけ、Aだけが離れない)
- 見出しや区切りがはっきりしている(章・項目の境界が分かる)
- 「結論」が文のどこかに必ず含まれている(前置きだけの文章が続かない)
- 同じ内容の重複が少ない(古い版・新しい版が混在しない)
FAQを「1ページに全部」よりも「カテゴリごとにページ分割」しておくと、後でチャンクが暴れにくいです。
ウェブサイト同期なら、ナビゲーションや関連記事リンクが大量に入るページは、できればFAQ本文だけのページに寄せるか、同期対象を絞れるなら絞ったほうが安定します。
対応形式と容量制限:分割の考え方(プラン差に注意)
データソース画面を見ると分かる通り、Difyは取り込めるファイル形式がかなり多いです(PDF、DOCX、Markdown、CSV、HTMLなどが想定されます)。
ただし、ファイルの形式よりも実務でつまずきやすいのは「サイズと上限」です。
数字は環境やプランで変わりますので、まずはあなたの画面に出ている上限を一度確認しておくのが安全です。
上限に引っかかりそうなときは、次の考え方で分割すると後工程もラクになります。
- 大きいPDFを無理に1つで入れないで、「章」や「手順」単位で分ける
- 1ファイルに“別テーマ”を詰め込まない(検索で拾ったときに混ざりやすい)
- 更新される資料は、更新単位に合わせてファイルを分ける(差し替えが簡単)
ここまで整えると、このあと扱う「チャンク設定」の調整が、かなり素直に効くようになります。
次の章では、キャプチャのチャンク設定画面を見ながら、どこをどう触ると精度が変わるのかを具体的に進めます。

チャンク設定の基本:最大長・オーバーラップ・区切りで精度を作る
この章では、ナレッジ設定の中でも一番「効きやすい」チャンク設定を扱います。
ここが整うと、検索で拾ってくる文章が“答えとして使いやすい形”になり、回答のブレが一気に減ります。
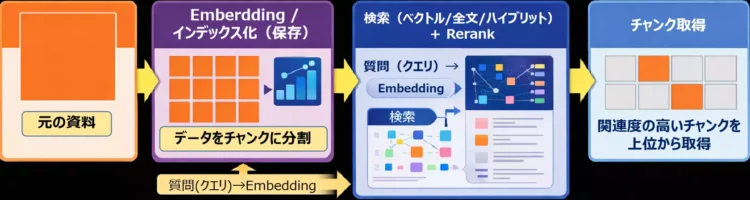
チャンクとは:検索で拾われる最小単位
Lesson5-1のFAQボットで、同じ質問をしても回答が微妙に違ったり、根拠がズレたりしたことがあると思います。
あれは多くの場合、モデルの気まぐれというより「拾ってきた文章の中身が毎回ちょっと違う」ことが原因です。
チャンク設定は、その“拾われ方”をコントロールします。
イメージとしては、資料を適切なサイズのカードに切り分けて、検索がそのカードを持ってくるようにする作業です。
カードが大きすぎると関係ない文が混ざり、逆に小さすぎると必要な前後関係が切れてしまいます。
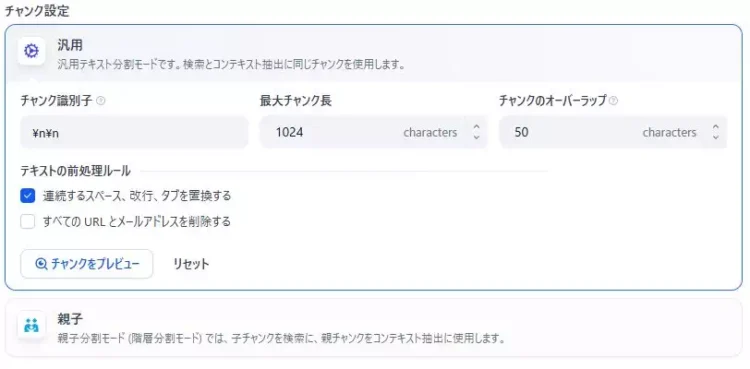
汎用モードの項目の読み方(識別子/最大長/オーバーラップ)
キャプチャの上部に「汎用」というモードがあり、ここでチャンクの基本ルールを決められます。
最初はこの汎用モードで問題ありません。大事なのは「それぞれの項目が、どんな失敗を防ぐためのものか」を押さえることです。
まず見えている主な項目は、次の3つです。
- チャンク識別子
- 最大チャンク長(characters)
- チャンクのオーバーラップ(characters)
ここからは、初心者がつまずきやすい順に説明します。
最大チャンク長:1チャンクに入れる“根拠の量”を決める
この画像では、最大チャンク長が「1024 characters」になっています。これは「1チャンクに入れてよい文字数の上限」を決めるものです。
FAQチャットボットでズレが出る典型パターンは、チャンクが大きすぎて、1つのチャンク内に別の話題まで入ってしまうケースです。
たとえば「休暇申請の手順」と「経費精算の注意点」が同じチャンクに混ざると、検索が当たっていても回答が混線しやすくなります。
逆に小さすぎると、QとAが分断されたり、手順の前提が欠けたりして、回答が断片的になります。
ポイントはチャンク1つが「質問に対して、そのまま根拠として貼れる文章量」になっているかどうかです。
まずはキャプチャのように1000前後から始めて、次の章で紹介するプレビューを見ながら調整すると失敗しにくいです。
オーバーラップ:境界の取りこぼしを防ぐ
キャプチャでは、オーバーラップが「50 characters」になっています。これは、隣り合うチャンクの境界部分を少し重ねる設定です。
オーバーラップが役立つのは、結論が文末にあり、次の段落に補足が続くような資料です。
境界で話が切れてしまうと、検索で拾ったチャンクだけでは意味が取りにくくなります。そこで、少しだけ重ねることで、境界にある重要な一文を取りこぼしにくくします。
ただし、重ねすぎると似た文章が増えて、検索結果が“同じようなチャンクだらけ”になり、ノイズが増えることがあります。
まずはキャプチャの50程度を起点にして、境界で切れて困るときに少し増やす、くらいの扱いがちょうどいいです。
チャンク識別子:どこで分割するか
チャンク識別子は、文章をどの単位で区切り始めるかに関わります。デフォルトでは、改行(段落)をベースに区切るような指定になっています。
「\n\n」は改行を意味するんだね。
ここで意識したいのは「資料の書き方に合った区切り方にする」ことです。
FAQのようにQとAが段落でまとまっている資料なら段落区切りが相性が良いです。一方で、見出しの付け方が独特だったり、改行が少ない資料だと、区切りが不自然になってチャンクが偏ることがあります。
この項目は “理屈だけで決める” より、プレビュー結果を見て判断するのが確実です。次の見出しで、その確認方法を具体的に見ていきます。
前処理(空白整理・URL削除):検索ノイズを減らす
テキストの前処理ルールとして、2つのチェック項目があります。
- 連続するスペース、改行、タブを置換する
- すべてのURLとメールアドレスを削除する
前処理は、資料の見た目を整えるというより「検索の邪魔になるノイズを減らす」ためにあります。
たとえばPDF由来のテキストで、変な改行や余計な空白が大量に入っていると、チャンクが読みづらくなったり、意図しない位置で分割されたりします。
そういうときは、置換のチェックが効きます。
一方で、URLやメールアドレスを削除する設定は、資料の性質を見て判断してください。
FAQで「申請フォームはこちら」のリンクが根拠として重要なら、消すと逆に不便になります。
困ってからONにするのではなく、「この情報は回答に必要か?」で決めるのが安全です。
プレビューで確認する4ポイント
チャンク設定で一番大事なのが「チャンクをプレビュー」です。ここを見ずに数値だけ変えると、改善したつもりで悪化することがよくあります。
プレビューでは、次の点を確認してください。
- FAQなら、1つのQとAが同じチャンク内に収まっているか
- 見出しだけのチャンクが大量にできていないか
- 1チャンクの中で話題が飛んでいないか(別テーマが混ざっていないか)
- 逆に、手順の途中で不自然に切れていないか(前提が欠けていないか)
チェックは“全部完璧”を狙う必要はありません。
まずは「よく聞かれる質問2〜3個」を想定して、その答えの根拠になりそうな部分が、気持ちよく1チャンクに収まっているかを見ます。
ここが通れば、次の検索設定が素直に効き始めます。
親子(階層)分割は、長い規程やマニュアルで効く
ここまで汎用モードについて解説してきましたが、チャンク設定には「親子モード」というものもあります。
これは、子チャンクで検索しつつ、親チャンクを回答用の文脈として使う、といった“階層型”の分割方法です。
ただ、社内規程や手順書のように章立てが明確で、1つのトピックが長く続く資料では、親子分割が効くことがあります。検索でピンポイントに当てつつ、回答には上位の文脈も一緒に渡せるからです。
ここは無理に最初から触らず、「汎用でやってみたけど、前後関係がいつも欠ける」という症状が出たときの選択肢として覚えておくくらいで大丈夫です。
文章を読むのに疲れてきた?
ここで一度、Lesson5-1で作った社内FAQチャットボットのナレッジを再設定してみよう!
ただし一度登録したナレッジは後から変更できない項目もあるので、また一から作ることになるかな。
プレビューを見ながら色々いじってみよう!

インデックス方法(高品質 / 経済的)の違い
チャンク設定の次に迷いやすいのが「インデックス方法」です。
ここは一言でいうと、ナレッジを検索しやすくするために、Difyが資料をどう処理して “引き出し” にしまうかを決める場所です。
同じ資料でも、ここを変えると「取り出せる情報の質」と「コスト感」が変わってきます。
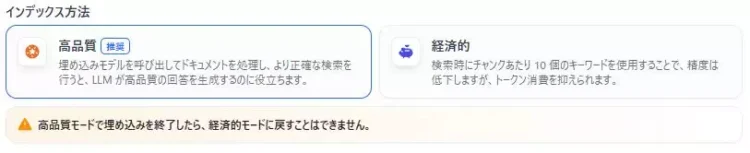
インデックス方法は大きく2つに分かれています。どちらが正解というより、目的に合うほうを選びます。
ざっくり整理すると、次のような違いです。
| 高品質 | より丁寧にドキュメントを処理して、検索の当たりやすさを優先します。 FAQボットの「ズレ」を減らしたいときに効きやすい選択です。 |
| 経済的 | トークン消費などのコストを抑えながら運用しやすくする方向です。 大量の資料をまず入れて回したいときに向いています。 |
ポイントは、「高品質=必ず正しい」「経済的=使えない」ではないことです。
差が出るのは、質問が曖昧だったり、資料が長文だったり、似た情報が多かったりするときです。
埋め込みモデルの選び方:検索ヒットの質を左右する
「埋め込みモデル」は「検索の当たり方に関わる土台の部品」を選ぶもの(≒LLM)です。
うまく選べていれば、同じチャンク設定・同じ検索設定でも“ヒットの質”が上がりやすくなります。

埋め込みモデルの役割:文章を検索向けベクトルに変換
RAGでは、質問文とナレッジの文章を “近さ” で照合して、関係がありそうなチャンクを取りにいきます。
埋め込みモデルは、そのために文章を「意味が近いもの同士が近くに並ぶ形」に変換してくれる役割です。
ここを押さえておくと、設定の見方が変わります。
たとえば「検索が弱い」と感じたとき、トップKや閾値だけでなく、「そもそも“近さ”の計算が得意なモデルになっているか?」も疑えるようになります。
最初はデフォルトでOK(先にチャンク/検索を整える)
結論から言うと、最初はキャプチャでデフォルトとして選ばれている埋め込みモデルのまま進めて問題ありません。
というのも、埋め込みモデルの差が効いてくるのは、次のような状況が揃ったときが多いからです。
- 資料量が増えて、似た内容がたくさん混ざってきた
- 固有名詞・型番・社内用語が多く、質問の言い回しがぶれやすい
- 日本語と英語が混在していて、検索が不安定になっている
つまり、まずはチャンクと検索設定(トップKや閾値)を整えて、ボトルネックが本当に埋め込み側にあるかを見極めるほうが、遠回りになりません。
埋め込みモデル見直しサイン(言い換え・多言語・専門用語)
「変えるべきかどうか」で悩むときは、症状から判断するのが一番ラクです。
次のような現象が続くなら、埋め込みモデルの見直しを検討してもいいサインです。
- 言い換えに弱い(同じ意味の別表現だと急にヒットしない)
- 日本語の質問で、関係あるのに拾えないチャンクが増える
- 用語が短いと当たらないのに、長く説明すると当たる(近さの判断が不安定)
このあたりは「検索設定をいじっても限界がある」と感じたときに効いてきます。
検索方式の選び方:ベクトル / 全文 / ハイブリッドの使い分け
ここからは「どう探して持ってくるか」を決める検索設定です。
Lesson5-1のFAQボットで感じたズレは、チャンク設定だけで改善することも多いですが、それでも「ヒットしない」「関係ない文章が混ざる」が残る場合は、検索側の調整が効いてきます。
基本的にはハイブリッド検索を選んでおくと良いでしょう。
ベクトル検索:トップK・スコア閾値の調整ポイント
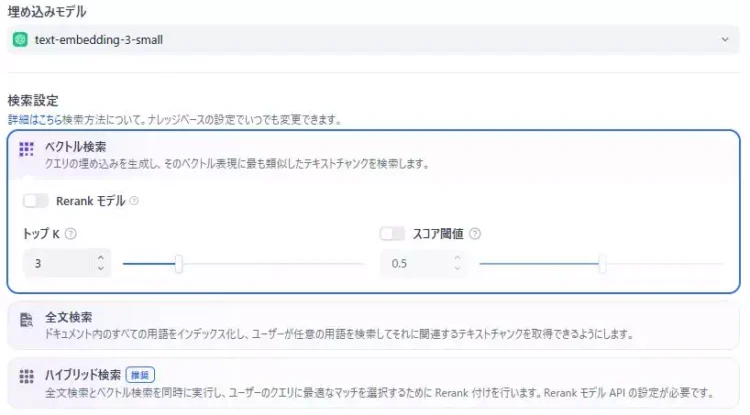
ベクトル検索は、質問文と「意味の近いチャンク」を探して取ってくる方式です。
FAQのように言い回しが揺れる場面でも、ある程度うまく拾えることが多いので、基本はここを軸に考えると迷いにくいです。
ここでよく触るのが、トップKとスコア閾値です。どちらも「候補の出し方」を調整するつまみで、症状に直結します。
トップKは「候補を何件持ってくるか」
トップKを増やすと、拾える情報は増えます。その反面、関係ないチャンクも混ざりやすくなるので、回答が散る原因にもなります。
最初の段階では、いきなり大きくするより、小さめで様子を見るのが扱いやすいです。
たとえば「答えが当たっている時は、だいたい上位数件に根拠が入っている」なら、トップKを増やす必要はあまりありません。
一方で、次のようなときはトップKを増やす余地があります。
- 質問に対して、根拠が複数箇所に分かれている(手順+注意点など)
- 似たチャンクが多く、上位だけだと外れを引きやすい
スコア閾値は「弱い一致を切り捨てる線引き」
スコア閾値は、近さが一定以下の候補を落とすための設定です。
ここが低すぎると、関係ないチャンクまで入ってきてノイズが増えます。逆に高すぎると、そもそも何も取れずに「ナレッジが使われない」状態になります。
調整のコツは、いきなり大きく動かさないことです。
特に「ヒットしない」問題を閾値だけで解決しようとすると、別の質問で急に拾えなくなったりします。まずはトップKとセットで、少しずつ試す方が安全です。
全文検索が向く質問:型番・エラー文・制度名
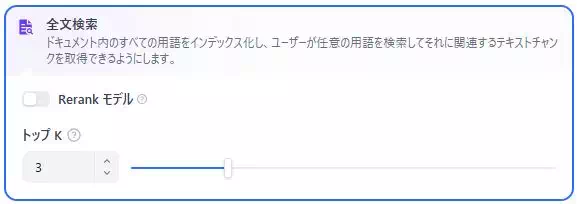
全文検索は、文章に含まれる単語を手掛かりに探す手法です。
FAQでも、意味検索より文字一致が強い場面があります。たとえば型番、エラー文、制度名、申請フォーム名のように、単語そのものが重要な質問です。
こういう質問が多いナレッジなら、全文検索を検討する価値があります。
ベクトル検索は言い換えに強い一方で、短い固有名詞や記号混じりの文字列は取りこぼすことがあるためです。
ただし、全文検索は資料の書き方に強く影響されます。
資料内に同じ単語がたくさん出てくる場合、ヒットはするけれど候補が広がりすぎてノイズが増えることもあります。
なので「固有名詞系の質問だけ弱い」といったピンポイントの症状があるときに使うのが向いています。
Rerank:順位の精度を上げる
Rerankは、いったん集めた候補(トップK)を、別のモデルで精密に並べ替える仕組みです。
これが効くのは「候補は集まるけど、上位に外れが来る」タイプの問題です。つまり、検索の“取りこぼし”より“順位の精度”に困っているときに強いです。
Rerankは便利ですが、設定画面の案内にある通り、モデルの準備やコストが関わります。いきなりONにするより、次のような順で検討すると失敗しにくいです。
- まずトップKと閾値で、候補が安定して取れる状態を作る
- それでも順位が安定しないときに、Rerankを導入する
ハイブリッド検索は「意味」と「文字」を両方見る
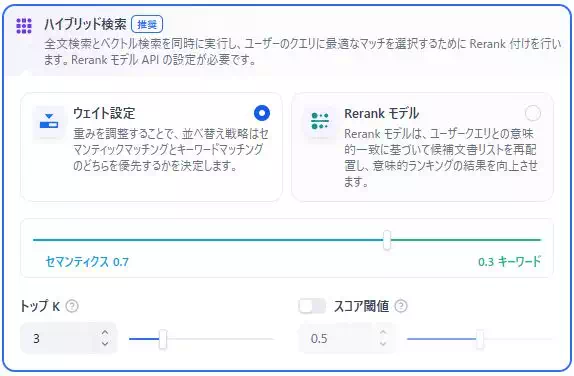
ハイブリッド検索は、ベクトル検索と全文検索を組み合わせる方式です。
「意味では拾えるけど固有名詞に弱い」「固有名詞は拾えるけど言い換えに弱い」といったケースで、両方の欠点を補いやすくなります。
ただし、組み合わせる分だけ挙動が複雑になりやすいのも事実です。
まずはベクトル検索を基準に作って、弱点がはっきりしてからハイブリッドに移ると、調整がスムーズになります。
まとめ
Lesson5-2では、ナレッジ設定を「データソース」「チャンク」「検索」の3つに分けて、どこを触ると何が変わるのかを整理しました。
迷ったときは、次の順番に立ち戻るのが一番ラクです。
- まずチャンクをプレビューして、区切りが自然かを確認する(ここが崩れると全部ズレます)
- 次に検索設定で、トップKとスコア閾値を小さく動かして症状を切り分ける
- 候補は取れているのに順位が不安定なら、Rerankを“最後のひと押し”として使う
次のLesson5-3では、同じナレッジでもさらに賢く答えさせるために、クエリ変換やメモリ活用といった「質問の扱い方」を強化していきます。
- 記事改善アンケート|ご意見をお聞かせください(1分で終わります)
-
本サイトでは、みなさまの学習をよりサポートできるサービスを目指しております。
そのため、みなさまの意見をアンケート形式でお伺いしています。1分だけ、ご協力いただけますと幸いです。
(※)APIキーや個人情報等は入力しないようお願いします。
【Dify】記事改善アンケート
<<前のページ
Difyの記事一覧
次のページ>>