Dify学習館|生成AIアプリ開発の基礎から実践まで
【Dify】LLMノードの詳細設定方法と考え方|チャットフローとワークフロー
ながみえ

Difyでアプリを作り始めると、気になってくるのが「LLMノードの設定って、どこをどう触ればいいの?」という部分だと思います。
モデルを選んでプロンプトを書けば動く一方で、少し複雑なアプリにすると、回答のブレ・コスト・失敗時の挙動などがじわじわ効いてきます。
この記事では、LLMノードの設定画面にある項目を「どういう目的で使う設定か」「どのタイミングでONにするか」という観点で整理していきます。
難しい専門用語を増やすのではなく、あなたがこの先、実務や副業のアプリ開発で迷わないための“地図”を作るつもりで進めます。
Difyの教科書|生成AIアプリ開発の基礎から実践まで
“Difyの教科書” はDifyを用いた生成AIアプリ開発を体系的に習得できる学習サイトです。
初心者からでも手順に沿って進めるだけでアプリを作れるようになり、業務効率化や副業にも活かせる内容になっています。
ぜひ、ご活用ください^^


【Dify】利用料金はいくら?Cloud・セルフホスト・Premium/Enterpriseの費用を比較

【Dify】入力フォーム設計入門|変数・フィールド設計ミニ講座

【Dify】LLMに任せないほうがいい文章と安全な扱い方

【Dify】システム変数の種類と使い方一覧

【Dify】定型文が崩れる原因|敬語・トーン・禁止表現のガード設計
LLMノードは何をする場所?|チャットフローとワークフローの共通点
まず押さえておきたいのは、チャットフローでもワークフローでも、LLMノードがやっていることの本質は同じだという点です。
違いは「会話として続くことを前提にするか」「処理として一連の手順を前提にするか」という使い方の側にあります。
そのうえで、LLMノードはだいたい次の3つの仕事をしています。
この3つを意識しておくと、後の章で出てくる「メモリ」「構造化出力」「失敗時再試行」などの設定が、“何のために存在するのか” が一気に腹落ちします。
- 入力を受け取る(ユーザーの質問、前段ノードの結果、ファイルなど)
- 指示に従って推論する(SYSTEM/USERメッセージ、テンプレ、制約条件)
- 出力を返す(通常の文章、決まった形式、次のノードへ渡す値)
チャットフロー:会話を崩さないためのLLM設計ポイント
チャットフローの場合、LLMノードはユーザーとのやりとりの中心に置かれやすく、「会話の流れを壊さない」ことが重要になります。
たとえば同じ質問でも、前の発言を踏まえて説明を続けてほしい場面は多いですよね。
ここで効いてくるのが後半で扱うメモリ設定や、どの情報をコンテキストとして渡すか、という設計です。
逆に言うと、チャットフローではLLMノードの設定が雑だと、会話が噛み合わない・言い回しがブレる・必要な前提を毎回聞き返される、という形でストレスが出やすくなります。
ワークフロー:次ノードが扱いやすい出力に寄せる
ワークフローの場合、LLMノードは「この工程では要約」「次の工程では分類」「最後に文章を整形」といった形で、役割を分割して使うことが増えます。
このとき大事なのは、“会話として自然か”よりも、“次のノードが扱いやすい形で返す”ことです。
たとえば、後続で条件分岐やデータ保存をしたいなら、自由な文章よりも項目が揃った出力(構造化出力)や、変数として受け渡ししやすい形式が役に立ちます。
LLMノードの設定を詰めるほど、ワークフロー全体が安定して、手戻りが減ります。
ここから先、LLMノードの設定項目を見ていくと、いろいろスイッチが並んでいて“設定の森”に迷いがちです。
そんなときは、いま整理した「入力・指示・出力」のどこを調整する設定なのか、に立ち戻ってください。
あわせて読みたい

【Dify】Lesson2-5:Difyの5つのアプリタイプの違いと選び方
LLMノード設定画面の全体像
LLMノードの設定は、項目が多いぶん「どこに何があるか」を最初に掴めるかどうかで、その後の理解スピードがかなり変わります。
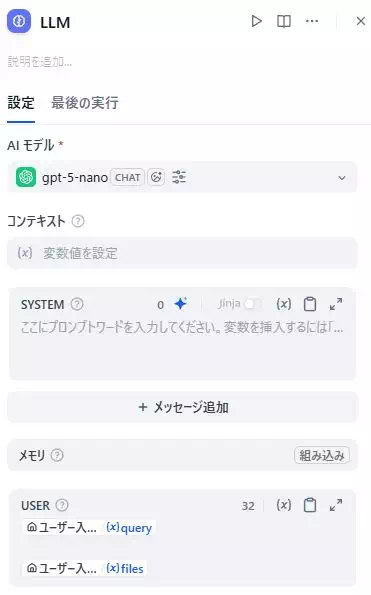
設定画面の上半分は「入力」と「指示」を作る場所
上側の設定(上の画像)は、ざっくり言うと「LLMに何を渡して、どう振る舞わせるか」を決めるエリアです。
ここが固まると、回答のトーンや品質が安定しやすくなります。
- AIモデル:どのモデルで推論するかを選ぶ
- コンテキスト(変数値を設定):前段の結果など“材料”を渡す入口
- SYSTEM:アプリ全体の方針や制約を書く場所(ここが中核)
- メッセージ追加:必要に応じて会話の部品を増やす
- USER:ユーザー入力やファイルをLLMに渡す設定
ここでのポイントは、「SYSTEMで方針を固め、USERで入力を渡す」 のが基本形だということです。
コンテキストは、その間を補強する“追加の材料”という位置づけで捉えると迷いにくいです。
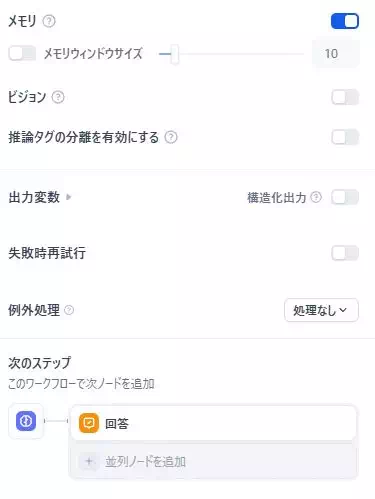
設定画面の下半分は「出力」と「安定性」を整える場所
下側の設定(下の画像)は、「出力をどう扱うか」「運用で困りがちな部分をどう吸収するか」を決めるエリアです。
アプリを実務で使うほど、ここが効いてきます。
- メモリ(ON/OFF)とメモリウィンドウサイズ:会話の保持範囲を調整
- ビジョン:画像を扱うときのスイッチ
- 推論タグの分離を有効にする:推論と回答の扱いを分けたいときに関係
- 出力変数/構造化出力:次のノードで使いやすい形に整える
- 失敗時再試行/例外処理:エラー時の挙動を安定させる
- 次のステップ:このノードの出力をどこへ渡すか
「動くアプリ」から「壊れにくいアプリ」にしていくとき、だいたいこの領域に戻ってきます。
特に、構造化出力 と 失敗時再試行 は、後から効いてくる“保険”になりやすいです。
最初に触るおすすめ順(迷ったらこの流れ)
全部を一気に完璧にしようとすると、逆に手が止まりやすいです。そこで、この記事では“迷いにくい順番”を先に共有しておきます。
おすすめは、次の順番で最低限を固めてから、必要なものだけ追加していく流れです。
- AIモデル:まずは1つに固定して比較しやすくする
- SYSTEM:アプリの役割・禁止事項・出力条件を明確にする
- USER(query / files):入力が正しく渡っているかを確認する
- メモリ:会話を保持したいときだけONにして、範囲を調整する
- 構造化出力/出力変数:次のノードで扱う必要が出たら整える
- 失敗時再試行/例外処理:運用を意識する段階で追加する
次の章からは、この画面に並んでいる項目をひとつずつ取り上げて、「いつ使うべきか」「ONにしたら何が変わるか」を具体的に説明していきます。
まずはこの章の内容で、設定画面を“地図”として見られる状態になっていればOKです。
AIモデルの選び方:品質・速度・コストで決める
LLMノードの設定で、いちばん最初に目に入るのが「AIモデル」の欄です。
ここをどう選ぶかで、回答の品質だけでなく、レスポンス速度やコスト感、さらには“アプリとしての安定感”まで変わってきます。
ただ、初心者のうちはモデル候補がいくつも並ぶと迷いやすいですよね。
これに関しては、OpenAI限定ですが専用の記事がありますので、そちらを参照してください↓↓
あわせて読みたい

【Dify】OpenAIモデルの選び方|用途別おすすめ早見表【2026年版】
コンテキスト/変数の基本:材料を分離して渡す
AIモデルを選んでSYSTEMを書いたのに、思った通りの回答にならないとき、原因は「LLMに渡している材料が足りない(または多すぎる)」ことがよくあります。
その材料を整理して渡すための入口が、設定画面にある「コンテキスト(変数値を設定)」です(上の画像で“コンテキスト”と表示されている部分ですね)。
ここでやることを一言で言うなら、LLMに渡す情報を「後から使いやすい形で束ねる」ことです。
プロンプトに全部ベタ書きするより、運用がラクになり、アプリの拡張もしやすくなります。
コンテキストの役割:SYSTEM/USERと分けて材料を渡す
コンテキストは、SYSTEMやUSERの本文とは別枠で、LLMに渡す情報をまとめる場所です。
チャットフローでもワークフローでも、アプリが少しだけ複雑になると「ユーザーの入力(query)以外の情報」も一緒に渡したくなります。
たとえば、前のノードで作った要約、分類結果、チェック項目、注意事項などです。
こういう情報を、毎回SYSTEMに長々書き足していくと、プロンプトが肥大化して管理が難しくなりがちです。
そこで、コンテキストを使って“材料は材料として分離する”と、プロンプト設計が安定します。
たとえば、次のようなものがコンテキストに向いています。
- 前段ノードの出力(要約結果、抽出結果、分類ラベルなど)
- アプリ固有の前提情報(社内用語、出力に必要な定義、注意点)
- ユーザー入力を補助する情報(フォームの入力値、選択した条件など)
変数で渡すと、プロンプトが「差し替え可能」になる
「変数値を設定」とある通り、コンテキストは変数とセットで考えると便利です。
変数として持っておくと、SYSTEMやUSERの文章の中で必要なところに差し込めるので、同じテンプレを使い回しやすくなります。
ここでのコツは、変数を“文章の一部”として扱うよりも、“意味のある部品”として扱うことです。つまり、名前を見ただけで役割が分かる単位にします。
たとえば、こんな分け方だと後で困りにくいです。
- summary:前段で作った要約
- target_audience:想定読者(初心者向け、社内向け、など)
- output_format:出力の形式条件(箇条書き、表形式の代替、など)
- constraints:禁止事項や注意事項(断定しない、外部リンクを書かない、など)
こうしておくと、「アプリを別用途に流用したい」「条件だけ切り替えたい」という場面で、プロンプト本文をいじらずに済みます。
コンテキスト過多を防ぐ:必要最小限→追加の順で調整
コンテキストは便利ですが、入れれば入れるほど良いわけではありません。
材料が多すぎると、LLMが何を優先すべきか迷いやすくなり、回答が長くなったり、論点が散ったりします。
判断の目安はシンプルで、「その回答に本当に必要な材料か?」です。
たとえば、文章の要約アプリなのに、長い参考情報や関係ない定義を大量に渡すと、要約がぼやける原因になります。
もし迷ったら、次の順で整理すると失敗しにくいです。
- まずは必要最低限の材料だけをコンテキストに入れる
- 出力が安定しない場合に限って、追加の材料を少しずつ足す
- 足した結果、逆にブレたら、材料の量を減らす方向で調整する
SYSTEMプロンプト設計:アプリの方針と制約を固定する
LLMノードの設定項目の中で、「ここが決まると一気に安定する」という意味でいちばん重要なのが SYSTEM です。
“Difyでアプリとして運用しやすいSYSTEM”に絞って書き方を整理します。
なお、具体的な記述方法については専用の記事がありますので、↓↓を参照してください。
あわせて読みたい

【Dify】Lesson2-6:良いプロンプトの書き方
SYSTEMの基本:固定ルールで出力ブレを減らす
SYSTEMは、LLMに対して「このアプリではこう振る舞ってね」という最上位のルールを渡す場所です。
USER(queryなど)が毎回変わるのに対して、SYSTEMは基本的に固定で、アプリの性格と品質を支えます。
同じプロンプトでも、SYSTEMが弱いと出力がブレやすくなります。
逆にSYSTEMが強いと、ユーザーが雑に入力しても“それっぽく整った回答”を返せるようになります。
Jinja2/変数挿入でSYSTEMをテンプレ化する
SYSTEM欄に「Jinja」という表示があるのは、SYSTEM内でテンプレ記法を使えるからです。
Difyでは、USERの query や前段ノードの出力などを変数として持てるので、SYSTEMに直接ベタ書きせず「差し替え可能な部品」として扱えます。
たとえば、入力や条件をこういう形で埋め込むと、アプリの拡張が一気に楽になります。
入力:
- ユーザーの依頼:{{query}}
- 追加条件:{{constraints}}
- 出力形式:{{output_format}}このように“可変の情報は変数に寄せる”と、SYSTEMはルールに集中できて、結果的にブレが減りやすいです。
チャット/ワークフローでSYSTEMの狙いを切り替える
チャットフローでは、SYSTEMは「会話としての一貫性」を支える役割が強いです。
口調・確認の仕方・前提の置き方など、ユーザー体験に直結するルールが効きます。
一方でワークフローでは、SYSTEMは「出力を次工程で扱える形に固定する」役割が強くなります。
雑談を減らし、項目が揃った出力や構造化を意識したルールが向いています。
USER設計:今回の依頼と入力を分けて渡す
LLMノードのUSER欄は、ひとことで言うと「その場その場で変わる依頼文」を置く場所です。
SYSTEMが“アプリの憲法”だとすると、USERは“今回の案件の依頼書”に近いイメージですね。
ここをうまく設計すると、同じSYSTEMでも用途を変えて使い回しやすくなります。
USERに書くもの:タスク・入力・今回だけの制約
USER欄は、固定ルールではなく「今回やってほしいこと」「判断に必要な材料」を素直に書くのが基本です。
逆に、毎回同じ注意事項や口調指定までUSERに寄せると、後から修正するときに散らばって事故りやすくなります。
たとえばUSER欄に向いているのは、次のような内容です。
- 入力データ(文章、条件、箇条書きのメモなど)
- その場だけの制約(今回だけ「300字で」「3案出して」など)
SYSTEMと役割を分けると、回答がブレにくい
USER欄を設計するときのコツは、「どこまでSYSTEMで固定して、どこからUSERで変動させるか」を最初に決めることです。
ここが曖昧だと、同じ指示がSYSTEMとUSERで二重に出て矛盾し、回答がぶれます。
分担のおすすめはシンプルで、次の方針が使いやすいです。
- SYSTEM:口調、禁止事項、出力の基本フォーマット、推測の扱い、品質基準
- USER:今回の依頼、今回の入力、今回だけの条件

このサイトでは、USERはあまり使わずSYSTEM欄を多く使っています。
簡単なアプリならそれで問題ないけど、外部取得テキストを含んだ変数が多かったり、SYSTEMに書くプロンプトが長くて保守しにくい場合はUSERも使った方がいいよ。
USER分割の型:指示/本文/追加条件で分ける
Difyではメッセージを追加して複数のUSERメッセージとして積めます。これを使うと、LLMが読み間違えにくくなります。
分け方の定番は、次のように“段落の役割”で分割することです。
- 1通目:タスクの指示(何をするか)
- 2通目:入力データ(対象の本文)
- 3通目:追加条件(今回だけの縛り)
「全部まとめて1通」にすると、入力本文が長いときに“どれが指示でどれが材料か”が混ざりやすいので、分けられるなら分けた方が安定します。
USER設計チェックリスト(混在・重複・区切り不足)
最後に、USER欄の設計で崩れやすいポイントだけ短くまとめます。出力が不安定になったら、まずここを疑うと原因特定が早いです。
- 指示と入力が混ざっていて、LLMが「どれが材料か」迷っていないか
- SYSTEMとUSERで同じ指示を別表現で繰り返して矛盾していないか
- “今回だけの条件”があちこちに散っていないか(USERに寄せる)
- 入力が長いときに、区切り(見出しやラベル)がなくて読みにくくなっていないか
次の章では、会話の継続性に直結する「メモリ設定(ON/OFFとメモリウィンドウサイズ)」を扱います。
USER欄がきれいに設計できていると、メモリをONにしたときも挙動が読みやすくなります。
メモリ設定:ON/OFF判断とウィンドウサイズ調整
チャットフローのLLMノードにある「メモリ」は、チャットアプリを“会話っぽく”するための重要なスイッチです。
ワークフローには設定項目自体ありません。
メモリのON/OFFと「メモリウィンドウサイズ」をどう決めるかで、LLMの挙動がかなり変わります。
この章では、メモリを「便利だからとりあえずON」ではなく、アプリの目的に合わせて使い分けるための考え方を整理します。
あわせて読みたい

【Dify】Lesson5-3:賢いRAGアプリを作ろう|クエリ変換とメモリ活用
メモリONの効果:直近履歴をプロンプトに含める
メモリをONにすると、直近の会話履歴(ユーザーとアシスタントのやり取り)が、次の応答を作る材料としてLLMに渡されます。
つまり、LLMが「さっきまで何を話していたか」を踏まえて返せるようになります。
ここで大事なのは、メモリは“学習”ではなく、“今回の会話で参照できる材料が増える”という性質だという点です。
なので、会話が長くなるほど文脈を引き継げる一方で、余計な情報も混ざりやすくなります。
メモリは便利さと引き換えに、ブレやすさとコストが増えることがある、というイメージを持っておくと設計がラクです。
使い分け:会話重視はON/処理安定はOFF
メモリを使うかどうかは、「前の発言が次の発言に必要か?」で決めるのが一番シンプルです。
会話の自然さが必要なアプリほどONが効きますし、処理を安定させたいほどOFFが効きます。
判断の目安として、こんな使い分けがよくあります。
- ONが向くケース:要件ヒアリング、壁打ち、段階的に条件を詰める相談、同じテーマで会話が続くチャット
- OFFが向くケース:単発の要約、定型文生成、分類、変換など「毎回入力が完結している」タスク、ワークフローの部品としてのLLM
迷ったらまずはOFFで動きを固めて、必要になったらONにするほうがトラブルが少ないです。
メモリウィンドウサイズ調整:必要な文脈の寿命で決める
メモリウィンドウサイズは、ざっくり言うと「どれくらい前までの会話を参照材料に含めるか」を決めるつまみです。
大きくすると文脈がつながりやすくなりますが、そのぶん入力が増えるのでコストが上がったり、話題が混ざって回答が散ったりすることがあります。
決め方のコツは、会話の中で“必要な情報の寿命”を考えることです。
- 直前の条件だけ覚えていれば十分:小さめでOK
- 途中で決めた前提(目的・制約・対象)がずっと効く:やや大きめが有利
実務でおすすめなのは、最初から大きくするのではなく「小さめ→不足を感じたら増やす」です。
具体的には、会話が噛み合わなくなった瞬間に「何が足りなかったか」を見て、必要な範囲だけウィンドウを広げると、過剰なメモリで崩れるのを防げます。
メモリ起因のブレ対策:サイズ縮小・要点化など
メモリをONにしたときの典型的なトラブルは、「過去の流れに引っ張られて、今の依頼に集中しない」ことです。
特に、話題転換をしたのに前のテーマを混ぜて返してくる、という形で出やすいです。
こういうときは、次の方向で対処すると立て直しが早いです。
- メモリウィンドウサイズを小さくする(混入を減らす)
- SYSTEM側に「話題が切り替わったら前提を更新する」ルールを追加する
- 会話をリセットする導線を用意する(ユーザー体験としても親切)
- 長期の文脈が必要なら、会話履歴をそのまま渡すのではなく“要点だけのまとめ”にして渡す設計に寄せる
次の章では、画像や資料を扱いたいときに関係してくる「ビジョン(画像・ファイルを見せたいときの設定)」を解説します。
メモリと同じく、ONにするとできることが増える一方で、設計の考え方が必要になるポイントです。
ビジョン設定(画像入力):ONの判断基準と注意点
LLMノードで「画像を読み取って説明してほしい」「スクショの内容から手順を案内してほしい」といったアプリを作るなら、下側の設定にある「ビジョン」が重要になります。
画像(LLM_チャットフロー下)にもスイッチとして表示されている通り、これは“視覚入力を扱える状態にするかどうか”を切り替えるための設定です。
画像入力でできること/苦手なこと(読み取り限界)
ビジョンをONにすると、LLMが画像の内容(画面キャプチャ、図、写真など)を材料として回答できるようになります。
たとえば「このエラー画面は何が原因?」「このUIのどこを押す?」のような、文字だけでは伝わりにくい状況で力を発揮します。
一方で、ビジョンは万能ではありません。
画像を“見て判断する”のは得意ですが、細かい文字が潰れている画像や、判読が難しい資料は精度が落ちやすいです。
なので、アプリとしては「画像が読み取りづらいときの逃げ道」を用意しておくと運用が安定します。
ONにするべきタイミングは「入力に画像が混ざる」瞬間
ビジョンは、常にONにしておくよりも「必要なときにON」が基本です。
理由はシンプルで、入力の種類が増えるほど、アプリの設計(プロンプト、エラー処理、コスト感)が変わるからです。
実務・副業でありがちな“ONにするべき場面”は、だいたい次の系統にまとまります。
- スクショ解説:設定画面の見方、操作手順の案内、エラー画面の原因整理
- 画像の内容説明:図の読み取り、画面の要点抽出、画像の要約
- 画像に基づく文章生成:商品画像から紹介文、資料画像から説明文 など
「文章だけで完結しているアプリ」にビジョンを足すと、できることは増えますが、同時にテスト観点も増えます。
なので、まずは“画像が本当に必要なユースケース”から入るのが安全です。
モデル側の対応もセットで確認する
ビジョンのスイッチだけONにしても、使っているモデルが画像入力に対応していなければ期待通りに動きません。
つまり、ビジョンは「設定」と「モデル選定」がセットです。
画像を扱う予定があるなら、モデル選びの段階で“画像対応かどうか”も前提に含めておくと、後で作り直しになりにくいです。
ここでのコツは、最初から高度なことを狙わず、まずは「画像の要点を説明させる」くらいのシンプルなタスクで動作確認することです。
複雑な判断(複数画像の比較、細部の数値読み取りなど)は、動いた後に段階的に伸ばす方が、原因切り分けがラクです。
ビジョンを使うときのSYSTEMプロンプトの小さな工夫
画像入力を扱うときは、SYSTEM側に“画像がある前提の読み方”を一言足すだけで、回答がかなり安定します。
たとえば次のような方向性です。
- 画像の内容を先に短く要約してから回答に入る
- 読み取れない部分があれば推測せず、「読めない」と明記して代替案を出す
- 操作案内なら、画面内の文言や位置関係を使って案内する(曖昧な指示を避ける)
ビジョンは便利な反面、LLMが“それっぽく言ってしまう”リスクもゼロではありません。
なので「不確かなときは不確かと書く」をルール化しておくと、アプリとしての信頼性が上がります。
うまくいかないときの見直しポイント
ビジョン周りで詰まったときは、原因がスイッチ単体ではなく、周辺設計にあることが多いです。
具体的には「モデルの対応」「画像の解像度や文字の見やすさ」「プロンプト側の指示の曖昧さ」のどれかがボトルネックになりがちです。
まずは、画像の目的を「要点説明」に寄せて簡単化し、そこから「抽出」「分類」「手順案内」と段階的に難易度を上げるのが、一番手戻りが少ない進め方です。
推論タグ分離:ログ追跡と回答品質を両立する設定
LLMノードの下側設定にある「推論タグの分離を有効にする」は、ざっくり言うと モデルが内部で考えたプロセス(推論) と ユーザーに返す最終回答 を分けて扱いやすくするための機能です。
アプリ開発で地味に効くのが、「回答はきれいに出したいけど、裏では何が起きているか追いたい」という場面。
ここでこの設定が役に立ちます。
この設定で何が変わるのか|推論と最終回答を分けるメリット
この設定をONにすると、LLMの出力のうち“推論タグとして扱う部分”と“最終回答として扱う部分”を分離しやすくなります。
結果として、ユーザーに見せる回答はスッキリ保ちつつ、デバッグや品質確認では「なぜその結論になったのか」を追えるようになります。
ただし、分離の挙動はモデルやプロンプト設計とも関係します。
ONにしただけで必ず理想の形になるというより、「分離しやすい前提」を整える設定、と捉えるとハマりにくいです。
ONにすると便利なケース
この機能が真価を発揮するのは、アプリが“運用モード”に入ってきたときです。
たとえば、次のような場面で効果が出やすいです。
まず前提として、あなたが見たいのは「ユーザー向けの答え」ではなく「アプリが崩れた原因」や「判断の根拠」になってきます。
- 出力がブレたときに、どの条件を重視していたかを確認したい
- 構造化出力が崩れる原因を、ログの観点で切り分けたい
- チームやクライアントに、設計意図や改善ポイントを説明したい
「ユーザーには余計な思考を見せない」「でも開発者は中身を追える」状態を作れると、改善が速くなります。
OFFのほうが良いケースもある
一方で、常にONが正解というわけでもありません。
特に“公開後の安定運用”を優先するなら、余計な要素を増やさない判断も大切です。
- そもそも推論を分離する必要がない(単純な生成・要約など)
- モデル側の出力が推論タグ前提ではなく、分離が安定しない
- できるだけシンプルな設定で、再現性を高めたい
アプリがまだ試作段階ならONでログを追い、固まってきたらOFFに戻す、という使い方も現実的です。
SYSTEMプロンプト側で“分離ルール”を軽く補強すると安定する
この設定を使うなら、SYSTEM側に「推論は推論として、回答は回答として出す」ことを短く明記しておくと、分離が安定しやすくなります。
長文で縛る必要はなく、次のように方針だけ置けば十分です。
推論は推論用のタグ内にまとめ、ユーザーに返す最終回答はタグの外に出力してください。 最終回答は簡潔に、結論→理由→手順(必要なら)の順で出力してください。
この程度でも、回答本文が“思考の混ざった文章”になりにくくなります。
特に、後半で扱う「構造化出力」と組み合わせる場合は、こうした整理が効いてきます。
よくあるつまずきと対処
最後に、運用で起きがちなズレだけ押さえておきます。
出力が期待と違うときは、設定のON/OFFより「プロンプトとモデルの相性」が原因になっていることも多いです。
- 推論っぽい文章が最終回答に混ざる → SYSTEMで「最終回答に含めない」ルールを一文追加
- 分離が安定しない → いったんOFFにして、まずは回答品質と構造を固める
- ログは追えるが回答が長くなる → 出力条件(文字数・構成)をSYSTEM側で再調整
次の章では、LLMの出力を次のノードで扱いやすくするための「出力変数・構造化出力」を解説します。
ここが整うと、ワークフローでもチャットフローでも“アプリっぽさ”が一段上がります。
出力変数と構造化出力のON/OFF(出力の扱い方)
LLMノードは「文章を返して終わり」にもできますが、Difyでアプリとして完成度を上げるなら、出力を“次の処理に渡しやすい形”に整えるのが重要になります。
「出力変数」や「構造化出力」は、そのための機能です。
ここを押さえると、ワークフロー型のアプリが一気に作りやすくなります。
出力変数は「次のノードに渡すための受け皿」
出力変数は、LLMが生成した結果を“名前付きの値”として保存するための仕組みです。
これがあると、後続ノードで「この文章をそのまま表示する」だけでなく、「別のLLMに渡して整形する」「条件分岐の材料にする」「通知文に差し込む」などがやりやすくなります。
運用で効くポイントは、出力を1つの長文として扱うよりも、「あとで使い回す単位」に分けて持てることです。
たとえば、最終回答とは別に“要点だけ”や“タイトル案だけ”を変数化しておくと、後からUIや処理を組み替えるときに強いです。
構造化出力は「機械が扱える形」で返させるための設定
構造化出力は、LLMの出力を自由文ではなく、JSONのような決まった形で返させたいときに使います。
アプリ開発でよくあるのが、「分類結果だけ欲しい」「必要項目を抜き出したい」「フォームに入れるデータが欲しい」といったケースで、こういうときに自由文だと後工程が不安定になりがちです。
構造化出力を使うと、次のノードが“文章を解釈する”負担が減り、全体が壊れにくくなります。
特に分岐や外部連携を入れたい場合は、早めに構造化へ寄せると後が楽です。
構造化出力を安定させるコツは「項目を欲張らない」
構造化出力でつまずきやすいのは、最初から項目を増やしすぎることです。
LLMは項目が多いほどミスしやすくなるので、最初は「このアプリに絶対必要な最小項目」に絞るのがコツです。
例えば「分類」なら、まずは label と reason くらいから始めて、運用上どうしても必要になったら confidence や suggestion を足す、という順番が安定します。
増やすのは簡単ですが、減らすのは意外と難しいので、最初は小さくが正解です。
SYSTEM側に「余計な文章を書かない」ルールを入れると崩れにくい
構造化出力を使うときは、SYSTEM(または追加メッセージ)に次の方針を短く入れておくと事故が減ります。
ポイントは、JSONの前後に解説文を書かせないことです。
出力は指定した形式のみで返してください。 前置き・解説・挨拶など、形式外の文章は一切出力しないでください。
この一文があるだけで、「JSONのあとに補足を書いてしまう」タイプの崩れを抑えやすくなります。
推論タグ分離をONにしている場合も、最終回答側は形式だけを出す、という設計に寄せると扱いやすいです。
失敗時再試行・例外処理(安定運用のための設定)
アプリを実際に使い始めると、「たまにうまく返ってこない」「急にエラーになる」といった“たまに発生する不具合”が気になってきます。
下側の設定にある 失敗時再試行 と 例外処理 は、そういう場面でユーザー体験を守るための保険です。
ここでは、細かいエラー原因の深掘りというより、「どんな設計だと困りにくいか」「どのタイミングでONにするか」を中心に整理します。
失敗時再試行は「一時的な失敗」を吸収するための設定
LLMや外部のAPIを使う以上、通信の一時的な失敗や、混雑によるタイムアウトのような“運が悪いだけ”の失敗はゼロにできません。
失敗時再試行をONにしておくと、そうした一時的な失敗に対して、同じ処理を自動でもう一度試すことができます。
特に、ユーザーが同じ操作をやり直すのが面倒なアプリほど、この設定が効きます。
逆に、処理が重い・コストが高い・同じ入力を何度も投げたくないケースでは慎重に扱うのがコツです。
失敗時再試行をONにするべきケースと、慎重にすべきケース
再試行を入れるか迷ったら、「失敗の原因が“たまたま”である可能性が高いか」で判断するとスッキリします。
例えば、次のようなケースはONにする価値が高いです。
- たまに応答が返らない/タイムアウトすることがある
- 1回の処理が短く、再試行しても負担が大きくない
- ユーザーに“もう一度押してください”と言いたくない
一方で、次のようなケースでは注意が必要です。
- 生成が長文でコストが高い(再試行でコストが増える)
- 入力が巨大で処理が重い(再試行が連鎖すると待ち時間が伸びる)
- 失敗の原因が入力や設計ミスの可能性が高い(再試行しても直らない)
つまり、再試行は“万能なエラー解決”ではなく、「一時的な失敗を吸収する」ための仕組みとして使うのが正解です。
例外処理は「失敗したときにどう振る舞うか」を決める
例外処理は、失敗が起きたときにアプリがどう動くか(あるいはどう動かないか)を決める設定です。
画像内では、例外処理の選択肢として「処理なし」などが見えるはずです。
ここでの考え方はシンプルで、「失敗したときにユーザーに何を返すと親切か」を先に決めます。
なにも決めないと、ユーザーから見ると“無反応”や“意味不明なエラー”になりやすく、アプリの信頼感が落ちてしまいます。
実務・副業向けにおすすめの「失敗時の落としどころ」
例外処理の設計は、凝り始めるとキリがないのですが、まずは最低限この方針だけ決めておくと運用がラクです。
- ユーザーに見せるメッセージは短く(原因の断定はしない)
- 次に何をすればいいかを必ず添える(再入力、短くする、もう一度試す、など)
- 開発者側には原因が追える情報を残す(ログや内部メッセージで確認できる形)
たとえばユーザー向けには、「通信が混み合っている可能性があります。
時間をおいて再度お試しください。」のように、行動につながる案内があるだけで体験が大きく変わります。
失敗が続くときは「再試行」より先に見るべきポイントがある
再試行や例外処理は“運用の補強”ですが、失敗が頻発するなら設定で隠すのではなく、根本の設計を見直した方が早いこともあります。
よくある見直しポイントは、次のような方向です。
- SYSTEMや出力条件が複雑すぎて、モデルが崩れている
- 構造化出力の項目が多すぎて、形式が安定しない
- 入力(コンテキスト)が多すぎて、必要情報が埋もれている
「たまに失敗」なら再試行・例外処理で吸収、「頻繁に失敗」ならプロンプトや出力設計に戻る、という切り分けができると、改善が速くなります。
まとめ:まずモデルとSYSTEM、必要に応じて機能を足す
LLMノードの設定は項目が多く見えますが、迷ったときは次の流れで整理するとブレにくくなります。
まずは AIモデル と SYSTEM を固めて、「このアプリは何を返すべきか」を安定させます。
次に、必要に応じて USER欄の設計 や コンテキスト(変数) で入力を整えていきます。
会話を自然につなげたいときは メモリ を、画像を扱いたいときは ビジョン を、運用で落ちにくくしたいときは 失敗時再試行・例外処理 を追加する、という順番です。
設定を一気に盛るより、最小構成で動かしてから、必要な機能だけ足すほうが結果的に早く完成します。
これからアプリを作り込むときは、今回の内容を「設定の地図」として使いながら、目的に合うスイッチだけ選んでいきましょう。
Dify学習館|生成AIアプリ開発の基礎から実践まで
【Dify】利用料金はいくら?Cloud・セルフホスト・Premium/Enterpriseの費用を比較
【Dify】入力フォーム設計入門|変数・フィールド設計ミニ講座
【Dify】LLMに任せないほうがいい文章と安全な扱い方
【Dify】システム変数の種類と使い方一覧
【Dify】定型文が崩れる原因|敬語・トーン・禁止表現のガード設計