【業務自動化】Chapter1-5|データを新規シートへ自動で振り分け

一つ前のページでは シートにデータを書き込む方法 について学習しました。
今回は データの自動振り分け について見ていきましょう。
Chapter1:PythonによるExcel自動化の基本を身につけよう
・Chapter1-1:openpyxlとは何か|インストールと動作確認
・Chapter1-2:PythonでExcelファイルを作成しよう
・Chapter1-3:Excelシートからデータを読み込もう
・Chapter1-4:Excelシートにデータを書き込もう
・Chapter1-5:データを新規シートへ自動振り分けしよう ◁今回はここ
・Chapter1-6:簡単なExcel自動化を体験しよう
Chapter2:自動化ツールを.exe化して配布しよう
Chapter3:現場で使える便利な自動化ツールを4つ作ろう
Chapter4:Webスクレイピングでデータを自動で集めよう
Chapter5:自動化ツールを作ってお金を稼ごう
Excelを日常的に扱っていると、「特定の条件ごとにデータを分類して別のシートに分けたい」と思う場面はよくあります。
たとえば、名簿を男女別のシートに振り分けたり、売上データを支店ごとに分けたりといった作業です。
手作業で行うと非常に面倒ですが、Pythonとopenpyxlを使えば自動でシートを作成し、条件に応じてデータを仕分けることができます。
この記事では、Excelの1つのシートにまとまったデータを、条件ごとに新しいシートへ自動で振り分ける方法を学んでいきます。
初心者でも理解できるように、コードの紹介から動作の仕組みまで丁寧に解説していきます。

<<前のページ

業務自動化の記事一覧

次のページ>>

条件別で新規シートへ自動振り分けする方法
この節では、openpyxlを使って既存のExcelデータを特定の条件(例:性別)ごとに分け、新しいシートを自動生成しながらデータを振り分けるプログラムを作成していきます。
前回作成したExcel資料「Chapter1-4.xlsx」を引き続き使用します。
資料がない方は↓↓の「make_workbook1-4.py」をコピーして適切な場所(※)に保存し、実行してください。
- make_workbook1-4.py
-
import pathlib from openpyxl import Workbook from openpyxl.styles import Font, PatternFill, Border, Side, Alignment from openpyxl.styles.colors import Color def create_chapter1_4_workbook(): file_path = pathlib.Path(__file__).parent / "workbooks" file_path.mkdir(exist_ok=True) save_path = file_path / "Chapter1-4.xlsx" workbook = Workbook() sheet = workbook.active sheet.title = "Sheet1" # 元ファイルに合わせた設定 sheet.sheet_format.defaultRowHeight = 18.75 sheet.sheet_format.defaultColWidth = 9 sheet.column_dimensions["B"].width = 11.625 sheet.column_dimensions["D"].width = 11.375 # データ rows = [ ["名前", "性別", "年齢", "年齢区分"], ["吉田 彩花", "女", 45, "成人"], ["小林 翔太", "男", 21, "成人"], ["長谷川 清", "男", 80, "シニア"], ["山田 大輔", "男", 40, "成人"], ["佐藤 陽翔", "男", 1, "未成年"], ["渡辺 亮", "男", 50, "成人"], ["伊藤 陽菜", "女", 12, "未成年"], ["木村 智子", "女", 75, "シニア"], ["鈴木 結衣", "女", 3, "未成年"], ["松本 健太", "男", 30, "成人"], ["石井 誠", "男", 70, "シニア"], ["中村 莉子", "女", 18, "未成年"], ["高橋 悠真", "男", 6, "未成年"], ["田中 美月", "女", 9, "未成年"], ["岡田 隆", "男", 60, "成人"], ["藤田 美穂", "女", 55, "成人"], ["山本 大和", "男", 15, "未成年"], ["村上 幸子", "女", 65, "シニア"], ["佐々木 真由", "女", 35, "成人"], ["加藤 愛美", "女", 25, "成人"], ] # スタイル base_font = Font(name="游ゴシック", size=11) header_fill = PatternFill( patternType="solid", fgColor=Color(theme=5, tint=0.4) ) thin = Side(style="thin", color=Color(auto=1)) header_border = Border(left=thin, right=thin, top=thin, bottom=thin) first_row_border_bd = Border(left=thin, right=thin, bottom=thin) first_row_border_c = Border(left=thin, bottom=thin) body_border_bd = Border(left=thin, right=thin, top=thin, bottom=thin) body_border_c = Border(left=thin, top=thin, bottom=thin) body_border_e = Border(left=thin, right=thin, top=thin, bottom=thin) header_alignment = Alignment(vertical="center") body_alignment = Alignment(vertical="center", wrap_text=True) empty_alignment = Alignment(vertical="center") start_row = 2 start_col = 2 # B列 for row_index, row_values in enumerate(rows, start=start_row): for col_index, value in enumerate(row_values, start=start_col): cell = sheet.cell(row=row_index, column=col_index, value=value) cell.font = base_font if row_index == 2: cell.fill = header_fill cell.border = header_border cell.alignment = header_alignment else: if col_index in (2, 4): # B列、D列 cell.border = first_row_border_bd if row_index == 3 else body_border_bd cell.alignment = body_alignment elif col_index == 3: # C列 cell.border = first_row_border_c if row_index == 3 else body_border_c cell.alignment = body_alignment elif col_index == 5: # E列 cell.border = body_border_e cell.alignment = empty_alignment workbook.save(save_path) print(f"{save_path} を作成しました。") if __name__ == "__main__": create_chapter1_4_workbook()
- (※)コードの保存場所について
-
コピーしたコードは以下の階層になるように保存して下さい。
この理由については、Chapter1-2 の記事で詳しく解説しています。
業務自動化学習/ # 学習フォルダ ├── Chap1/ # チャプター1の保存フォルダ │ ├── Chap1-5/ # チャプター1-5の保存フォルダ │ │ ├── Chapter1-5.py │ │ ├── make_workbook1-4.py # ☆ここに保存 │ │ └── workbooks/ │ │ ├── Chapter1-4.xlsx │ │ └── Chapter1-5.xlsx

Chapter1-4から続けて学習している人は、ExcelファイルをコピーしてChapter1-5のworkbooksフォルダに貼り付けよう!
自動振り分けのサンプルコード紹介|全体像と実行例

Excelデータを条件ごとに新しいシートへ振り分けるプログラムを紹介します。
以下のサンプルコードでは、既存のExcelファイルを読み込み、特定の列(ここでは「性別」の列)を基準にシートを作成してデータを仕分けています。
import openpyxl, pathlib # openpyxlとpathlibのインポート
file_path = pathlib.Path(__file__).parent / "workbooks" # エクセルファイルの保存フォルダの相対パスを作成
book = openpyxl.load_workbook(file_path / "Chapter1-4.xlsx") # ワークブックの読み込み
sheet = book.active # アクティブなシートを取得
HEADER_ROW_NO = 2 # 見出しが書かれている行番号
READ_START_ROW_NO = 3 # データ読み込みを開始する行番号
KEY_INDEX = 2 # 分類に使う列のインデックス番号(列番号ではない)
# 見出し行の値を取得してリストに格納
header_row_values = [] # 見出しの行を格納するリストの定義
for i in range(sheet.min_column-1, sheet.max_column+1):
header_row_values.append(sheet.cell(HEADER_ROW_NO, i).value)
# データ行を1行ずつ処理
for row in sheet.iter_rows(min_row = READ_START_ROW_NO): # 3行目以降をタプル形式で取得(中身はセルオブジェクト)
row_values = [] # 空のリストを定義
for cell in row: # 変数row内のデータ(セルオブジェクト)を順番に
row_values.append(cell.value) # 値だけ取り出してリストrow_valuesに代入
key_value = row_values[KEY_INDEX] # 性別(分類キー)を変数key_valueに代入
if key_value in book.sheetnames: # もしその性別のシートがあるならば
to_sheet = book[key_value] # そのシートを取得
else: # もし無いなら
to_sheet = book.create_sheet(title=key_value) # その性別のシートを作成し、
to_sheet.append(header_row_values) # 1行目に見出しを書き込む
to_sheet.append(row_values) # そのシートにリストrow_valuesの内容を書き込み
# ファイルを保存
book.save(file_path / "Chapter1-5.xlsx")このコードを実行すると、新規ブックchapter1-5.xlsxが作成されます。
そのブックには「男」と「女」という新しいシートが追加されており、適切に分類されているはずです。
ブックを直接開き、結果を確認して下さい。
サンプルコードの解説|処理の流れとポイント
このプログラムのポイントを順に解説します。
Excel処理の準備|ライブラリ導入とファイル指定
import openpyxl, pathlib # openpyxlとpathlibのインポート file_path = pathlib.Path(__file__).parent / "workbooks" # エクセルファイルの保存フォルダの相対パスを作成 book = openpyxl.load_workbook(file_path / "Chapter1-4.xlsx") # ワークブックの読み込み sheet = book.active # アクティブなシートを取得 HEADER_ROW_NO = 2 # 見出しが書かれている行番号 READ_START_ROW_NO = 3 # データ読み込みを開始する行番号 KEY_INDEX = 2 # 分類に使う列のインデックス番号(列番号ではない)
1行目から5行目まではここまで学習してきた内容と同じです。
必要なライブラリのインポート、ワークブックの保存場所のパス作成、そして実際にワークブックを開く処理をしています。
この部分に分からないところがある人は、Chapter1-2 の記事に戻って復習しましょう。
その後、データの読みとりに必要となる定数を定義しています。
ヘッダー取得|新規シートへ見出しを引き継ぐ準備
# 見出し行の値を取得してリストに格納
header_row_values = [] # 見出しの行を格納するリストの定義
for i in range(sheet.min_column-1, sheet.max_column+1):
header_row_values.append(sheet.cell(HEADER_ROW_NO, i).value)この部分では、既存のシートにある見出し(列名)を取得し、新しいシートにコピーできるよう準備しています。
これを後の処理で新しいシートに書き込み、どのシートにも同じ見出しを付けることで、データの見やすさと一貫性を保ちます。
- 列の範囲をループで回す
sheet.min_columnとsheet.max_columnを使って、シート内の列の最小番号と最大番号を取得- その範囲を
forループで繰り返し処理し、見出し行の値を1つずつ取り出す
- セルの値をリストに追加
sheet.cell(HEADER_ROW_NO, i).valueで「見出し行のi列目」の値を取得- 取得した値を
header_row_values.append(...)でリストに追加
最終的に、見出し行の値だけを集めたリストが完成します。
行を順番に読み込んでリスト化|iter_rows()メソッドの使い方
# データ行を1行ずつ処理
for row in sheet.iter_rows(min_row = READ_START_ROW_NO): # 3行目以降をタプル形式で取得(中身はセルオブジェクト)
row_values = [] # 空のリストを定義
for cell in row: # 変数row内のデータ(セルオブジェクト)を順番に
row_values.append(cell.value) # 値だけ取り出してリストrow_valuesに代入この部分では、Excelのデータ部分を1行ずつ読み込んで、扱いやすいPythonリストに変換 しています。
最初のfor文の中にある iter_rows()メソッド は、Excel シートの行をタプルとして効率的に読み込むためのメソッドです。
戻り値として行単位のセルオブジェクト(Cell インスタンス)を返します。
基本的な使い方は以下の通りです。
for row in worksheet.iter_rows(
min_row=None, # 開始する行番号 (デフォルトは 1)
max_row=None, # 終了する行番号 (省略するとシートの最終行まで)
min_col=None, # 開始する列番号 (デフォルトは 1, A列)
max_col=None, # 終了する列番号 (省略するとシートの最終列まで)
):各引数にNoneを代入するとデフォルト値が適用されます。また、デフォルト値を使用する場合は引数は省略することもできます。
すなわち、今回の提供コードは「データ読み込みを開始する行番号(=3行目)」からデータがある最後の行までを、4列のデータをタプルとして取得し、そのタプルをリストrow_valuesに格納しています。
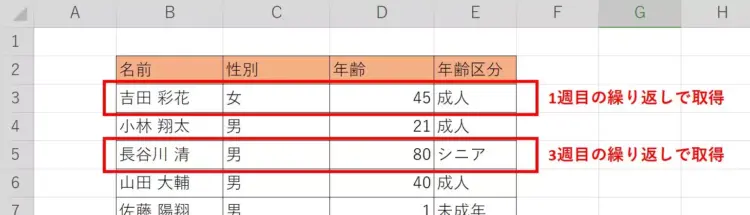
row_values = [3行目のタプル, 4行目のタプル, 5行目のタプル, ...] 3行目のタプル = (<Cell 'Sheet'.B3>, <Cell 'Sheet'.C3>, <Cell 'Sheet'.D3>, <Cell 'Sheet'.E3>) 3行目のタプル[0].value = 吉田 彩花 3行目のタプル[1].value = 女
振り分け処理|分類キーでシート選択・自動作成しappendで書き込む
key_value = row_values[KEY_INDEX] # 性別(分類キー)を変数key_valueに代入
if key_value in book.sheetnames: # もしその性別のシートがあるならば
to_sheet = book[key_value] # そのシートを取得
else: # もし無いなら
to_sheet = book.create_sheet(title=key_value) # その性別のシートを作成し、
to_sheet.append(header_row_values) # 1行目に見出しを書き込む
to_sheet.append(row_values) # そのシートにリストrow_valuesの内容を書き込みこの部分では、性別毎にシートを作成し、データを振り分けています。
- .sheetnamesプロパティ:その
Workbookに含まれるワークシート名のリストを返す - .create_sheet()メソッド:新しいワークシートをブックに追加
- .appendメソッド:指定したリストやタプルを「新しい行として」追加
振り分けられたデータ(タプル)は、最後の行でそのシートに書き込まれます。
保存|新規ブックとして出力
# ファイルを保存 book.save(file_path / "Chapter1-5.xlsx")
最後に、分類処理を終えたワークブックを新しいファイルとして保存して終了です。
まとめ|新規シートへ自動振り分けは業務自動化の基本
今回のサンプルでは、Excelのデータを特定の列を基準に自動で新規シートへ振り分ける方法を学びました。
openpyxlを使えば、手作業では面倒な「データ仕分け」も自動化できる- 条件に応じて新しいシートを作成し、ヘッダーをコピーして整った形式で保存できる
- 出力ファイルを別名で保存することで元データを守れる
こうした処理は、顧客リストの分類、商品カテゴリ別の売上管理、担当者別のタスク分けなど、ビジネスの現場で幅広く応用できます。
次のステップでは、さらに「簡単なExcel自動化」を体験し、実務に近い形で活用できるようにしていきましょう。
練習問題|シート分割を体験しよう
今回学習した内容を復習する練習問題に挑戦しましょう。

問題|Excelデータを年齢区分ごとに分類してシート作成
Excelファイルに記録されている人物データを処理し、年齢区分ごとにシートを分割して保存するプログラムを作成してください。
以下の要件に従ってコードを完成させて下さい。
- 入力ファイルは既存の Excel ファイル
Chapter1-5.xlsxを使用すること。 - 見出し行を保持し、データ行は 3 行目以降から処理を開始すること。
- 分類のキーは「年齢区分」の列を用いること。
- まだ存在しない分類のシートが必要になった場合は、新しいシートを作成し、先頭行に見出しを追加すること。
- 最終的に分類結果を同じExcelファイルに上書き保存すること。
正解サンプルコードと詳細解説
例えば以下のようなプログラムが考えられます。
- 正解コード例
-
import openpyxl, pathlib file_path = pathlib.Path(__file__).parent / "workbooks" book = openpyxl.load_workbook(file_path / "Chapter1-5.xlsx") sheet = book.active HEADER_ROW_NO = 2 READ_START_ROW_NO = 3 KEY_INDEX = 4 # 年齢区分(E列) # 見出し行をリスト化 header_row_values = [] for i in range(sheet.min_column-1, sheet.max_column+1): header_row_values.append(sheet.cell(HEADER_ROW_NO, i).value) # データ行を1つずつ処理 for row in sheet.iter_rows(min_row=READ_START_ROW_NO): row_values = [cell.value for cell in row] key_value = str(row_values[KEY_INDEX]) # 年齢区分(必ず文字列化) if key_value in book.sheetnames: to_sheet = book[key_value] else: to_sheet = book.create_sheet(title=key_value) to_sheet.append(header_row_values) to_sheet.append(row_values) # 保存 book.save(file_path / "Chapter1-5-answer.xlsx")
- 正解コードの解説
-
データ行を順番に読み込み、セルの値をリストに変換する処理
# データ行を1つずつ処理 for row in sheet.iter_rows(min_row=READ_START_ROW_NO): row_values = [cell.value for cell in row]この部分では、Excelシートの3行目以降のデータを1行ずつ取り出しています。
取り出した1行はセルの集まりなので、そのままでは扱いにくいため、セルの中の値だけを取り出してリストにまとめています。
これで、1行分の情報をPythonのリストとして使えるようになります。年齢区分をキーにシートを振り分け
key_value = str(row_values[KEY_INDEX]) # 年齢区分(必ず文字列化) if key_value in book.sheetnames: to_sheet = book[key_value] else: to_sheet = book.create_sheet(title=key_value) to_sheet.append(header_row_values) to_sheet.append(row_values)ここでは行ごとのデータから年齢区分を取り出して、その区分に合ったシートに書き込んでいます。
もしすでにその区分の名前を持つシートがあれば、そのシートにデータを追加します。
まだそのシートが存在しない場合は、新しいシートを作り、最初に見出し行を書いてからデータを追加します。
これによって、同じ年齢区分のデータがひとつのシートにまとまります。
記事改善アンケート
本サイトでは、みなさまの学習をよりサポートできるサービスを目指しております。
そのため、みなさまの意見をアンケート形式でお伺いしています。
1分だけ、ご協力いただけますと幸いです。
- 記事改善アンケート|ご意見をお聞かせください(1分で終わります)
-
【Excel業務自動化】記事改善アンケート
<<前のページ
業務自動化の記事一覧
次のページ>>
よくある質問(FAQ)|データを新規シートへ自動振り分けしよう
Q1. iter_rows() の基本と範囲指定は?最終行まで確実に読み取るコツを知りたい
本章では、データ読み取りに iter_rows() を用い、開始行だけを指定して最終行までを自動で走査する方針を採っています。
開始行(例:3行目)を設定すると、その行以降のデータ行がタプル(行単位のセル集合)として順に取得され、値だけを取り出して処理できるのがポイントです。
min_row や max_row などの引数は省略時に既定値が適用され、最終行までの読み取りが可能です。
実装解説でも、引数の意味と「3行目以降をタプルとして取得→値のリスト化」という流れが丁寧に整理されています。
Q2. 新規シートには見出し(ヘッダー)をどう引き継ぐ?append の役割は?
まず元シートの見出し行を抽出してリスト化し、分類先のシートを新規作成した直後に見出し行を最初に書き込むのが基本設計です。
これにより、どのシートにも同じ列構成が入り、見やすさと一貫性が保たれます。
そのうえで各データ行のリストを append で「新しい行として」末尾に追加していきます。
記事では「列の最小〜最大を走査して見出しを取得→新規シート作成時に見出しを書き込み→行データを順に append」という順序が示されています。
Q3. 分類キーが未知・空欄のときや、同名シートが既にあるときはどうなる?
処理は分類キーの値をもとに振り分けます。
該当名のシートが既にある場合はそのシートへ追記し、無い場合はシートを自動作成してから書き込みます。
これにより、データの追加・再実行にも強い安定したフローになります。
本記事のサンプルコードでは「性別」をキーに「男/女」シートを自動生成し、最終的に別名の新規ブックとして保存して完了します。
まとめ:開始行の明示+
iter_rows()で効率読み取り → ヘッダーを新規シートへ継承 → 既存なら追記/無ければ作成 → 別名で保存の流れが、現場運用でも拡張しやすい堅牢なパターンです。
<<前のページ
業務自動化の記事一覧
次のページ>>